Paper-grounded figure-to-video generation
Helping Figures Tell their Story!
Paper-Grounded Video Generation Explaining Complex Scientific Figures
Abstract
Scientific figures compress complex pipelines into a single canvas, yet understanding them requires paper-grounded, step-by-step narration aligned with visual highlights, a capability missing from current video generation systems and benchmarks.
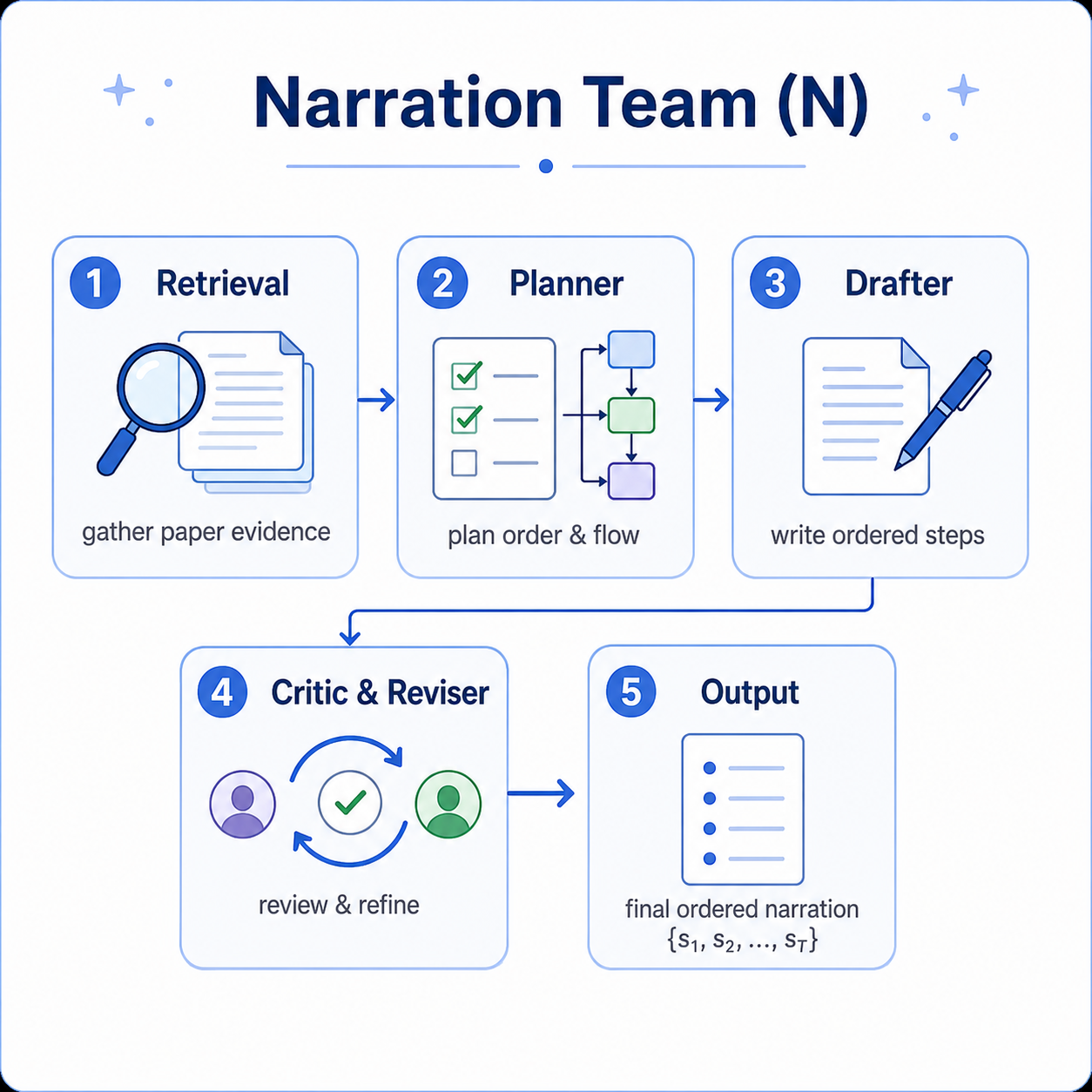
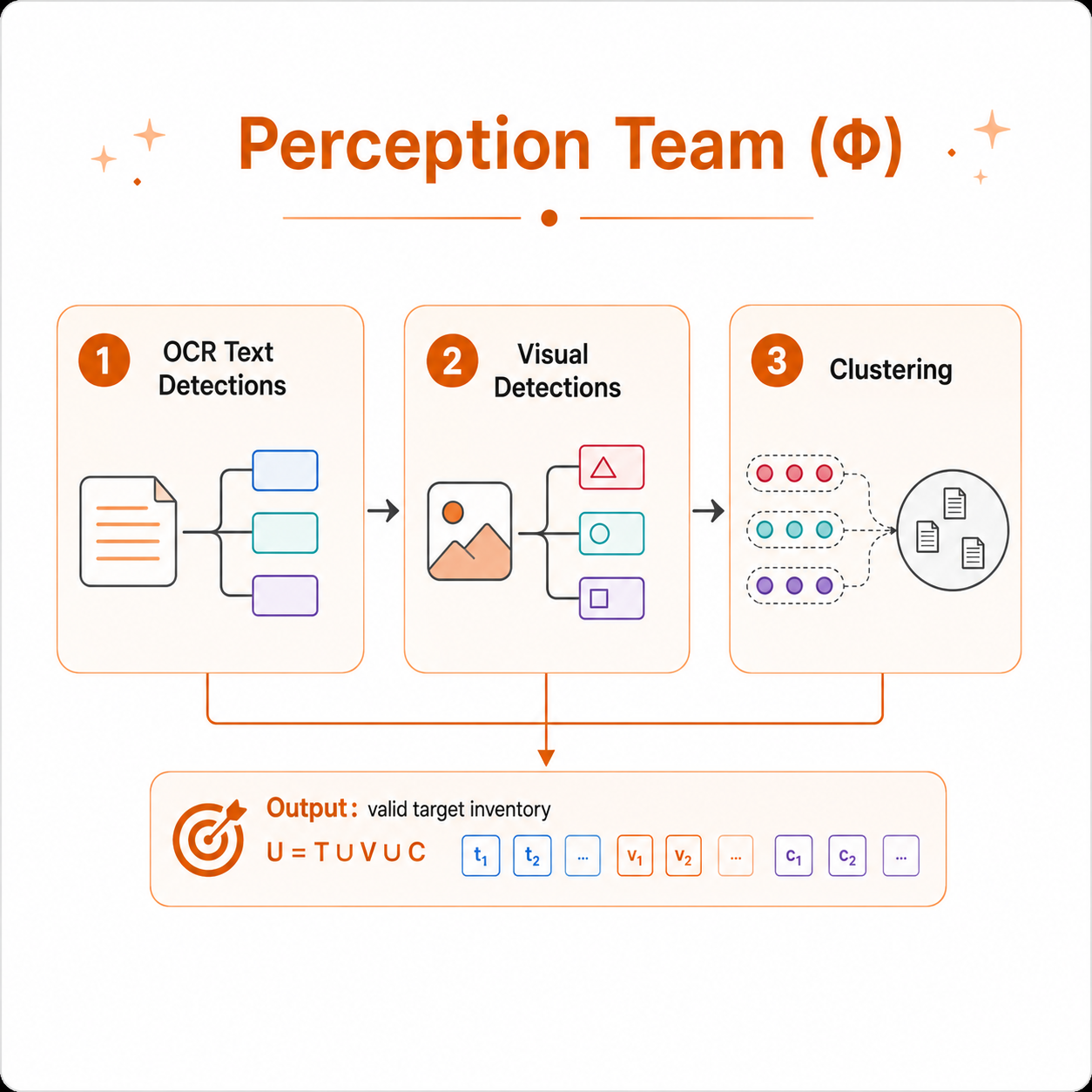
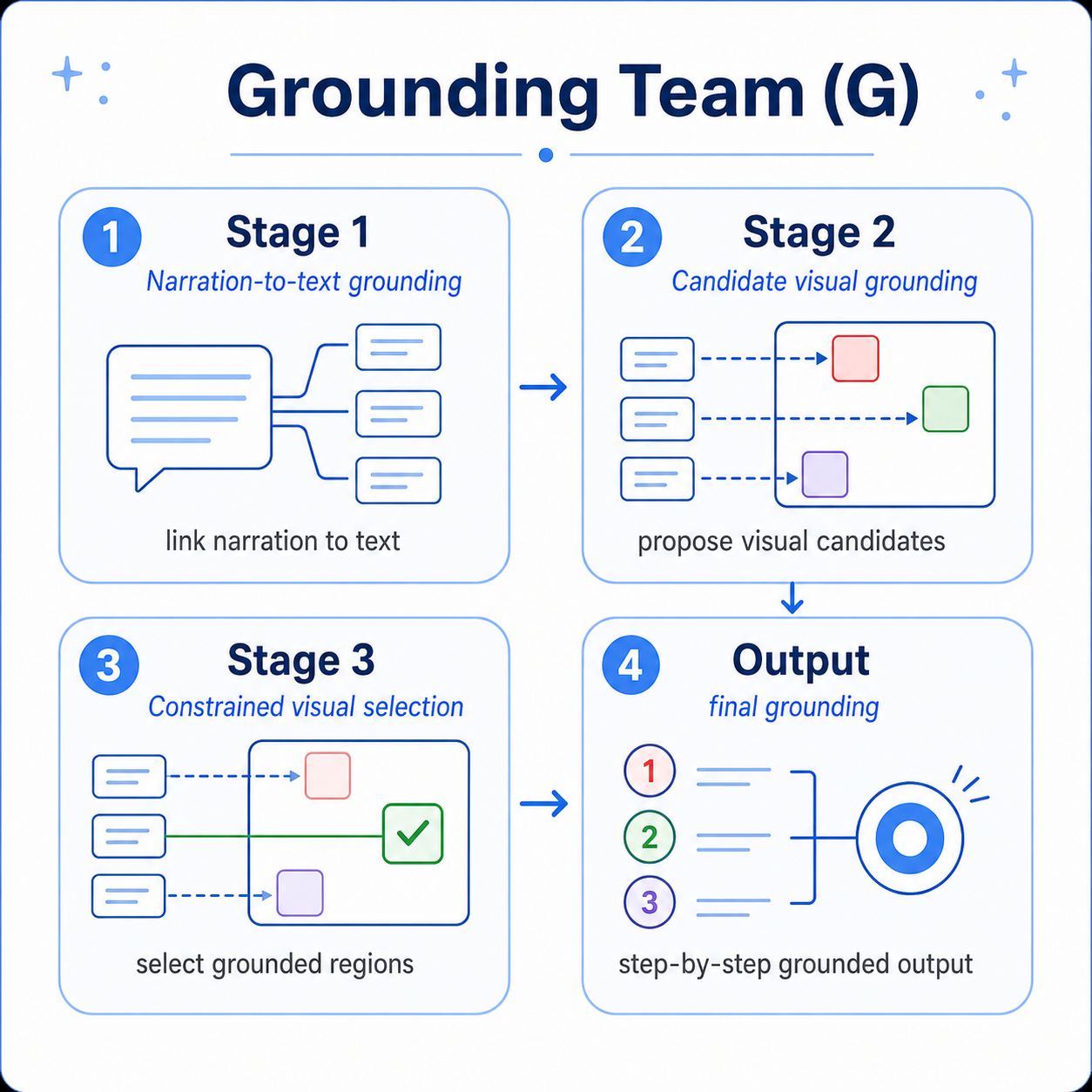
To address this, we introduce paper-grounded figure-to-video generation: generating narrated, region-grounded walkthrough videos from a figure and its paper. We propose MINARD (Multimodal Interpretation of Narrated Architecture via Region Decomposition), a pipeline that generates paper-grounded narrations and sequentially grounds them to figure regions. We also release FigTalk, a benchmark with new sequential and component-level grounding metrics derived.
On FigTalk, MINARD generates human-like, paper-faithful narrations and outperforms narration-conditioned figure spatial grounding compared to existing approaches in both automatic and human evaluation.
Example Job Comparison
Lecture exports rendered with grounding configurations, generated video, and ground truth highlights, using original video transcript.




Results
Grounding Evaluation on FigTalk-Extended
CF = Component Faithfulness, CC = Concept Coverage, EH = Excess Highlight Rate.
| MINARD | CF.84CC.79EH.09 | CF.79CC.74EH.12 | CF.81CC.76EH.10 | CF.77CC.72EH.14 |
|---|---|---|---|---|
| SAM+Box | CF.71CC.74EH.28 | CF.59CC.61EH.34 | CF.69CC.71EH.29 | CF.55CC.57EH.36 |
| VLM-Grnd. | CF.58CC.62EH.34 | CF.46CC.51EH.39 | CF.55CC.59EH.35 | CF.42CC.46EH.41 |
| SlideTalker | CF.42CC.45EH.48 | CF.33CC.36EH.53 | CF.40CC.43EH.50 | CF.30CC.33EH.55 |
| TEA | CF.24CC.27EH.58 | CF.17CC.20EH.66 | CF.22CC.25EH.60 | CF.14CC.17EH.69 |
| C2V-Image | CF.21CC.24EH.61 | CF.15CC.18EH.69 | CF.19CC.22EH.63 | CF.12CC.15EH.72 |
| Veo-3.1 | CF.18CC.21EH.62 | CF.11CC.14EH.71 | CF.16CC.19EH.65 | CF.09CC.12EH.74 |
| CogVideoX | CF.13CC.16EH.68 | CF.08CC.11EH.76 | CF.12CC.15EH.70 | CF.06CC.09EH.79 |
D1 Narration Quality
FigTalk-Gold narration quality by input regime and backbone.
| Figure-onlyF only | Gemini | 0.71 | 0.78 | 0.56 | 0.39 | 0.24 |
|---|---|---|---|---|---|---|
| Figure-onlyF only | Claude | 0.72 | 0.79 | 0.58 | 0.41 | 0.26 |
| Figure-onlyF only | GPT-5 | 0.73 | 0.80 | 0.60 | 0.43 | 0.28 |
| Paper2VideoF + D | Gemini | 0.66 | 0.77 | 0.54 | 0.31 | 0.39 |
| Paper2VideoF + D | Claude | 0.68 | 0.79 | 0.57 | 0.33 | 0.42 |
| Paper2VideoF + D | GPT-5 | 0.69 | 0.81 | 0.59 | 0.36 | 0.45 |
| MINARDF + D | Gemini | 0.74 | 0.80 | 0.75 | 0.70 | 0.74 |
| MINARDF + D | Claude | 0.75 | 0.82 | 0.79 | 0.76 | 0.78 |
| MINARDF + D | GPT-5 | 0.76 | 0.83 | 0.84 | 0.81 | 0.82 |